
Job Search Advice
YOUR RESUME
Your resume is your personal summary sheet. Your resume is the thing that gets your foot in the door. So, there's a few things you should do (and not do) to make it as awesome as you are.
Make your name BIG.
Your name has to stand out from everything else, because you want it to be remembered. Making it the biggest thing on the page is the easiest thing you can do to make that possible. I've seen soooo many resumes where the name is at the top, but it's just bolded and centered and they expect that to be enough. It's not.
Remove the objective.
Nobody looks at the objective. Nobody. I personally spoke to a bunch of recruiters from various companies and they all said that they never look at them. Use that space to talk about projects you've done, activities you've done, etc.
Keep it to a single page.
Recruiters are looking for a short summary of you. They're reading several resumes a day, and if they see something longer than they typically read, they could pass over yours for something more concise! If you'd like to say more, put a link to a personal website or portfolio for someone to find it. A resume is a summary, not a tome.
Remove irrelevant information.
I know that lifeguarding in high school was a good gig that helped you gain people skills and attention to detail. But you're in tech. That doesn't matter as much to tech companies. Sorry, buddy. I still think you're great with people. When you're a first semester freshman, it's okay to have old high school stuff on there, just because it's less likely that you have other things to put on your resume. But as soon as you have a college GPA to work with, a club or two, and some volunteer experiences to replace that, do it.
Don't make it a scavenger hunt.
When an application reviewer (engineer, recruiter, or otherwise) is looking over your resume, don't make it difficult for them to understand who you are and what you know.
For example, if you have online profiles like GitHub, LinkedIn, Twitter, or even your own personal website, put it on your resume. Don't make them have to search long and hard for you online if they want to know more!
If you decide to put relevant coursework on your resume, please, don't just put course numbers. Nobody knows what that means. And nobody is going to go to your university's website to find out exactly what CS229 is. Put down the course titles instead!
And finally, put down your graduation date. So many students I've seen don't put it on there because they are hiding the fact that they're a freshman, or they're "technically a junior if you count the credits." That doesn't matter. Trust me. Just put down your graduation date so that the company knows how much experience you have, and how soon they can potentially pull you in for full-time.
Include only certain personal information.
Companies aren't allowed to ask about your religion, marital status, or race/ethnicity, so you shouldn't include that.
In terms of contact information: you don't need your mailing address. That is a thing of the past. Just like my youth. Tech companies email, and maybe call. That's all you need! Some great things that you might also want to put on there are your personal website (if you have one, which you should), your GitHub profile (if you have one, which you should), and your LinkedIn (if you have one, which you should).
CV SAMPLE
Your cover letter is your written sales pitch. You've got a resume that summarizes everything. Now you have to write out a more complete, professional description of you and what you can offer a given company. Here's a sample cover letter to get you started:
Dear _________,
I hope your day is going well! My name is _________, and I'm a _________ at _________. I am very interested in working for _________ next _________. Your commitment to _________ and _________ that I saw on the website inspired me! The products you build and the values you stand for make _________ seem like an ideal workplace for me. A little about me, I [insert relevant work experience, extracurriculars, and projects here]. I think these experiences would make me a great candidate for you. Please let me know if there's anything else you need from me. I look forward to hearing from you! I can be reached at _________ and _________ Best regards,
Now, remember, this is just a sample. You can write a cover letter in any format you'd like. But, you should be sure to include the following:
Who - Who you are. Easy enough.
Where - Where you're coming from.
Why - Why you're interested in this company, and show that you researched them.
What - What you can bring to the table.
When - When you're available to start, and when they can contact you.
How - How they can reach you.
YOUR ATTITUDE
When you're internship/job hunting, it's very easy to feel down if you don't hear back from companies, an interview goes poorly, or you start comparing yourself to people. It's a tough field we're going into.
I want to emphasize something: You're brilliant. You're in this field for a reason. When your grades aren't awesome or someone gets something that you wanted, don't feel down on yourself. So many opportunities will come your way if you just keep working hard and refining your skills.
Mark Twain once said, "Comparison is the death of joy." When you start to compare your skills to others, it's hard to not feel as good about your own, or to get a little too competitive about your work. Work hard and don't let others get you down. It's remarkable how significantly that can improve both your work and your interviewing experience!
When you're talking to companies and recruiters at career fairs and hackathons and over the phone, be confident, not arrogant. Be grateful for the opportunity they're giving you, and smile! A great attitude will take you VERY far.
YOUR SKILLS
Obviously, your skills are what a company is buying from you when they hire you. So, honing in those skills and presenting them in an effective way is probably the most important thing in getting a gig.
Building Them
Chances are, if you've had a data structures and/or algorithms class, you're already going to do pretty well in the technical interviews. That is, if you can recall the information you learned.
Here's a checklist of things that you should probably be prepared to know in a technical interview:
Data types
Basic Bitwise Operations
String Operations
Arrays
Linked Lists
Singly Linked
Doubly Linked
Circular Linked
Queues
Stacks
Heaps
Trees
Binary Trees
Binary Search Trees
Tries
Self Balancing Trees
Traversing Trees
Breadth First Search - BFS
Depth First Search - DFS
Preorder, Inorder, Postorder
Graphs
Dijkstra's Algorithm / A* Search
Hash Maps
Handling Collisions
Sorting algorithms
Insertion
Selection
Merge
Quick
Time Complexities
This guide isn't for teaching you these skills. But there are several guides, problem sets, and practice systems out there that can help.
General Guides
Problem Sets
Online Judging Systems
Mock Interviews
Pramp - free
Careercup - paid
Gainlo - paid
Impact Interview - paid
Here's some books that might also be useful.
Typically, for an internship or your first job, questions won't get much more specific unless you're applying for a specific role. For example, if I wanted to be a mobile intern, I might be asked iOS/Android/Windows Phone specific questions, or if I wanted to be a web intern, I might be asked HTML/CSS/JavaScript questions, or if I wanted to be a backend intern, I might be asked about Django or Node or Ruby on Rails. That definitely depends on the company, and what you're both looking for.
Make sure you're able to implement and use the above data structures without the assistance of an IDE. Typically, onsite technical interviews involve coding on paper or a whiteboard, and phone/video interviews usually involve some kind of collaborative text editor. Yes, that means you won't have access to auto-complete, auto-compiling, or the internet to check for errors. So be ready for that!
Selling Them
When you're actively emailing and speaking with recruiters, they're going to ask you a lot of questions that are just checkboxes for what they're looking for in terms of skills.
If you've written anything in a language before, put it on your resume. A lot of companies have parsers that look for specific things that, again, will put a tick on those checkboxes before putting you through to the next round of review. Now, if you've only ever done "Hello, world!" in Python, don't say that you're a Python ninja or whatever. You don't want to be thrown into an interview that will only hurt your self-confidence. Speaking from experience. Trust me.
When a recruiter or engineer is asking you about a certain project you've done, or how you've used a particular language, be as specific as possible. Tell them exactly what you did on that particular project (or internship or what have you). Tell them how much you contributed, what languages you used, how long was the duration of development for that project, what was the outcome of the project, etc. etc.
For example, don't say, "I'm the webmaster for a club website. Next question." Okay, Dwight Schrute. Go back to your beet farm. Instead, say something more like this: "I developed and currently maintain the website for my university's computer science club. I built it from the ground up with HTML, CSS, JavaScript, and jQuery on the front-end. It's a static site, so a backend wasn't needed. The website's main function is to promote the club and give members crucial updates about meetings and events, and I update it regularly via a Python script I wrote." Oh my, you enchanting software engineer, you. Let me hire you.
When you're talking to companies about specific things you've done, make sure they know:
What? - What? - What did you make? What does it do? What impact has it made? What was the hardest part? What could you have done better?
Why? - Why did you make it? Was it for a hackathon, a school project, an open source contribution, or something else?
How? - With which technologies did you make this? Did you use a specific API? What parts of it did you work on?
When? - Did you do this recently or are you still living off of when you peaked in 10th grade?
Who? - Did you work on this with anyone? Who did what? Who is this for?
MY INTERESTS / RESOURCES:
Ansible
Awesome Lists
Epic Github Repos
Authentication
Data Science
Grafana
Docker
**Deploy Stacks to your Swarm: 🐳 **❤️
Logging:
Metrics:
Awesome Docker Repos
RaspberryPi ARM Images:
Docker Image Repositories
Docker-Awesome-Lists
Docker Blogs:
Docker Storage
OpenFaas:
Prometheus / Grafana on Swarm:
Logging / Kibana / Beats
Libraries
Frameworks
Continious Integration:
Circle-CI
Concourse
Jenkins
SwarmCi
Travis-CI
LambCI
DynamoDB
DynamoDB Docs
DynamoDB Best Practices
DynamoDB General Info
Elasticsearch
Elasticsearch Documentation
Elasticsearch Cheetsheets:
Elasticsearch Blogs
Elasticsearch Tools
Environment Setups:
Knowledge Base
KB HTTPS
Kubernetes
Kubernetes Storage
Golang
Great Blogs
Linuxkit:
Logging Stacks
Machine Learning:
Metrics:
MongoDB:
Monitoring
Monitoring and Alerting
Monitoring as Statuspages
Programming
Golang:
Java:
Python
Ruby:
Ruby on Rails:
Queues
Sysadmin References:
Self Hosting
Email Server Setups
Mailscanner Server Setups
Financial
Self Hosting Frameworks:
Serverless
VPN:
VPN-Howto:
Website Templates
Resume Templates
Web Frameworks
Python Flask:
Programming Language Resources
C++
Google uses clang-format (there is a command line "style" argument: -style=google)
Python
Other Language 1
Other Language 2
etc
FIND WORK PROGRAMMING 
Curated list of websites and resources to find work programming
Please read contribution guidelines before contributing.
Prepare
Coding Interview University - Complete computer science study plan to become a software engineer.
Free self taught CS education - Path to a free self-taught education in Computer Science.
LeetCode problems - Many problems geared for solving actual programming interview questions.
Learn Anything - Best paths for learning any topic including CS, programming and algorithms.
Algorithms - Solved algorithms and data structures problems in many languages.
Make CV
Awesome CV - Great LaTeX template.
Find work
HN: Who is Hiring - Search & filter through monthly
HN: Who is hiring?postings.Otta - Discover the most relevant roles for you at all of London's best startups.
findwork.dev - Jobs aggregator which collects data from Hacker News, Github, Stackoverflow.
Loom - Connecting companies and top freelancers.
Remote - Remote jobs for anyone, anywhere.
Key Values - Find engineering teams that share your values.
Future Jobs - The best machine learning, AI, and data science jobs, in one place.
CalmJobs - Work with companies who values work-life balance.
FOSS Jobs - Free & Open Source Jobs.
co-hire - Simple way for technical people to speak directly with technology companies.
Remoteleaf - Receive hand-picked remote jobs delivered straight to your inbox.
Find work by technology
iOS
iOS Dev Jobs - Has newsletter too.
Go
React
Python
Py Jobs - Search and post Python jobs all over the globe.
Rust
This week in Rust - Weekly Rust newsletter that has Jobs section.
Haskell
Haskell companies - Curated list of companies using Haskell in industry.
Freelancing
The Remote Freelancer - List of community-curated resources to find topical remote freelance & contract work.
Related


TECH INTERVIEW
ASYMPTOTIC NOTATION
Definition:
Asymptotic Notation is the hardware independent notation used to tell the time and space complexity of an algorithm. Meaning it's a standardized way of measuring how much memory an algorithm uses or how long it runs for given an input.
Complexities
The following are the Asymptotic rates of growth from best to worst:
constant growth -
O(1)Runtime is constant and does not grow withnlogarithmic growth –
O(log n)Runtime grows logarithmically in proportion tonlinear growth –
O(n)Runtime grows directly in proportion tonsuperlinear growth –
O(n log n)Runtime grows in proportion and logarithmically tonpolynomial growth –
O(n^c)Runtime grows quicker than previous all based onnexponential growth –
O(c^n)Runtime grows even faster than polynomial growth based onnfactorial growth –
O(n!)Runtime grows the fastest and becomes quickly unusable for even
small values of n
(source: Soumyadeep Debnath, Analysis of Algorithms | Big-O analysis) Visualized below; the x-axis representing input size and the y-axis representing complexity:
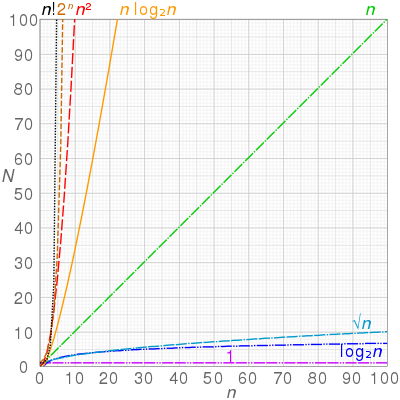
(source: Wikipedia, Computational Complexity of Mathematical Operations)
Big-O notation
Big-O refers to the upper bound of time or space complexity of an algorithm, meaning it worst case runtime scenario. An easy way to think of it is that runtime could be better than Big-O but it will never be worse.
Big-Ω (Big-Omega) notation
Big-Omega refers to the lower bound of time or space complexity of an algorithm, meaning it is the best runtime scenario. Or runtime could worse than Big-Omega, but it will never be better.
Big-θ (Big-Theta) notation
Big-Theta refers to the tight bound of time or space complexity of an algorithm. Another way to think of it is the intersection of Big-O and Big-Omega, or more simply runtime is guaranteed to be a given complexity, such as n log n .
What you need to know
Big-O and Big-Theta are the most common and helpful notations
Big-O does not mean Worst Case Scenario, Big-Theta does not mean average case, and Big-Omega does not mean Best Case Scenario. They only connote the algorithm's performance for a particular scenario, and all three can be used for any scenario.
Worst Case means given an unideal input, Average Case means given a typical input, Best case means a ideal input. Ex. Worst case means given an input the algorithm performs particularly bad, or best case an already sorted array for a sorting algorithm.
Best Case and Big Omega are generally not helpful since Best Cases are rare in the real world and lower bound might be very different than an upper bound.
Big-O isn't everything. On paper merge sort is faster than quick sort, but in practice quick sort is superior.
DATA STRUCTURES
Array
Definition
Stores data elements based on an sequential, most commonly 0 based, index.
Based on tuples from set theory.
They are one of the oldest, most commonly used data structures.
What you need to know
Optimal for indexing; bad at searching, inserting, and deleting (except at the end).
Linear arrays, or one dimensional arrays, are the most basic.
Are static in size, meaning that they are declared with a fixed size.
Dynamic arrays are like one dimensional arrays, but have reserved space for additional elements.
If a dynamic array is full, it copies its contents to a larger array.
Multi dimensional arrays nested arrays that allow for multiple dimensions such as an array of arrays providing a 2 dimensional spacial representation via x, y coordinates.
Time Complexity
Indexing: Linear array:
O(1), Dynamic array:O(1)Search: Linear array:
O(n), Dynamic array:O(n)Optimized Search: Linear array:
O(log n), Dynamic array:O(log n)Insertion: Linear array: n/a, Dynamic array:
O(n)
Linked List
Definition
Stores data with nodes that point to other nodes.
Nodes, at its most basic it has one datum and one reference (another node).
A linked list chains nodes together by pointing one node's reference towards another node.
What you need to know
Designed to optimize insertion and deletion, slow at indexing and searching.
Doubly linked list has nodes that also reference the previous node.
Circularly linked list is simple linked list whose tail, the last node, references the head, the first node.
Stack, commonly implemented with linked lists but can be made from arrays too.
Stacks are last in, first out (LIFO) data structures.
Made with a linked list by having the head be the only place for insertion and removal.
Queues, too can be implemented with a linked list or an array.
Queues are a first in, first out (FIFO) data structure.
Made with a doubly linked list that only removes from head and adds to tail.
Time Complexity
Indexing: Linked Lists:
O(n)Search: Linked Lists:
O(n)Optimized Search: Linked Lists:
O(n)Append: Linked Lists:
O(1)Prepend: Linked Lists:
O(1)Insertion: Linked Lists:
O(n)
Hash Table or Hash Map
Definition
Stores data with key value pairs.
Hash functions accept a key and return an output unique only to that specific key.
This is known as hashing, which is the concept that an input and an output have a one-to-one correspondence to map information.
Hash functions return a unique address in memory for that data.
What you need to know
Designed to optimize searching, insertion, and deletion.
Hash collisions are when a hash function returns the same output for two distinct inputs.
All hash functions have this problem.
This is often accommodated for by having the hash tables be very large.
Hashes are important for associative arrays and database indexing.
Time Complexity
Indexing: Hash Tables:
O(1)Search: Hash Tables:
O(1)Insertion: Hash Tables:
O(1)
Binary Tree
Definition
Is a tree like data structure where every node has at most two children.
There is one left and right child node.
What you need to know
Designed to optimize searching and sorting.
A degenerate tree is an unbalanced tree, which if entirely one-sided, is essentially a linked list.
They are comparably simple to implement than other data structures.
Used to make binary search trees.
A binary tree that uses comparable keys to assign which direction a child is.
Left child has a key smaller than its parent node.
Right child has a key greater than its parent node.
There can be no duplicate node.
Because of the above it is more likely to be used as a data structure than a binary tree.
Time Complexity
Indexing: Binary Search Tree:
O(log n)Search: Binary Search Tree:
O(log n)Insertion: Binary Search Tree:
O(log n)
ALGORITHMS
Algorithm Basics
Recursive Algorithms
Definition
An algorithm that calls itself in its definition.
Recursive case a conditional statement that is used to trigger the recursion.
Base case a conditional statement that is used to break the recursion.
What you need to know
Stack level too deep and stack overflow.
If you've seen either of these from a recursive algorithm, you messed up.
It means that your base case was never triggered because it was faulty or the problem was so massive you ran out of alloted memory.
Knowing whether or not you will reach a base case is integral to correctly using recursion.
Often used in Depth First Search
Iterative Algorithms
Definition
An algorithm that is called repeatedly but for a finite number of times, each time being a single iteration.
Often used to move incrementally through a data set.
What you need to know
Generally you will see iteration as loops, for, while, and until statements.
Think of iteration as moving one at a time through a set.
Often used to move through an array.
Recursion Vs. Iteration
The differences between recursion and iteration can be confusing to distinguish since both can be used to implement the other. But know that,
Recursion is, usually, more expressive and easier to implement.
Iteration uses less memory.
Functional languages tend to use recursion. (i.e. Haskell)
Imperative languages tend to use iteration. (i.e. Ruby)
Check out this Stack Overflow post for more info.
Pseudo Code of Moving Through an Array
Greedy Algorithms
Definition
An algorithm that, while executing, selects only the information that meets a certain criteria.
The general five components, taken from Wikipedia:
A candidate set, from which a solution is created.
A selection function, which chooses the best candidate to be added to the solution.
A feasibility function, that is used to determine if a candidate can be used to contribute to a solution.
An objective function, which assigns a value to a solution, or a partial solution.
A solution function, which will indicate when we have discovered a complete solution.
What you need to know
Used to find the expedient, though non-optimal, solution for a given problem.
Generally used on sets of data where only a small proportion of the information evaluated meets the desired result.
Often a greedy algorithm can help reduce the Big O of an algorithm.
Pseudo Code of a Greedy Algorithm to Find Largest Difference of any Two Numbers in an Array.
This algorithm never needed to compare all the differences to one another, saving it an entire iteration.
Search Algorithms
Breadth First Search
Definition
An algorithm that searches a tree (or graph) by searching levels of the tree first, starting at the root.
It finds every node on the same level, most often moving left to right.
While doing this it tracks the children nodes of the nodes on the current level.
When finished examining a level it moves to the left most node on the next level.
The bottom-right most node is evaluated last (the node that is deepest and is farthest right of it's level).
What you need to know
Optimal for searching a tree that is wider than it is deep.
Uses a queue to store information about the tree while it traverses a tree.
Because it uses a queue it is more memory intensive than depth first search.
The queue uses more memory because it needs to stores pointers
Time Complexity
Search: Breadth First Search: O(V + E)
E is number of edges
V is number of vertices
Depth First Search
Definition
An algorithm that searches a tree (or graph) by searching depth of the tree first, starting at the root.
It traverses left down a tree until it cannot go further.
Once it reaches the end of a branch it traverses back up trying the right child of nodes on that branch, and if possible left from the right children.
When finished examining a branch it moves to the node right of the root then tries to go left on all it's children until it reaches the bottom.
The right most node is evaluated last (the node that is right of all it's ancestors).
What you need to know
Optimal for searching a tree that is deeper than it is wide.
Uses a stack to push nodes onto.
Because a stack is LIFO it does not need to keep track of the nodes pointers and is therefore less memory intensive than breadth first search.
Once it cannot go further left it begins evaluating the stack.
Time Complexity
Search: Depth First Search: O(|E| + |V|)
E is number of edges
V is number of vertices
Breadth First Search Vs. Depth First Search
The simple answer to this question is that it depends on the size and shape of the tree.
For wide, shallow trees use Breadth First Search
For deep, narrow trees use Depth First Search
Nuances
Because BFS uses queues to store information about the nodes and its children, it could use more memory than is available on your computer. (But you probably won't have to worry about this.)
If using a DFS on a tree that is very deep you might go unnecessarily deep in the search. See xkcd for more information.
Breadth First Search tends to be a looping algorithm.
Depth First Search tends to be a recursive algorithm.
Sorting Algorithms
Selection Sort
Definition
A comparison based sorting algorithm.
Starts with the cursor on the left, iterating left to right
Compares the left side to the right, looking for the smallest known item
If the left is smaller than the item to the right it continues iterating
If the left is bigger than the item to the right, the item on the right becomes the known smallest number
Once it has checked all items, it moves the known smallest to the cursor and advances the cursor to the right and starts over
As the algorithm processes the data set, it builds a fully sorted left side of the data until the entire data set is sorted
Changes the array in place.
What you need to know
Inefficient for large data sets.
Very simple to implement.
Time Complexity
Best Case Sort: Merge Sort:
O(n^2)Average Case Sort: Merge Sort:
O(n^2)Worst Case Sort: Merge Sort:
O(n^2)
Space Complexity
Worst Case:
O(1)
Visualization

(source: Wikipedia, Insertion Sort)
Insertion Sort
Definition
A comparison based sorting algorithm.
Iterates left to right comparing the current cursor to the previous item.
If the cursor is smaller than the item on the left it swaps positions and the cursor compares itself again to the left hand side until it is put in its sorted position.
As the algorithm processes the data set, the left side becomes increasingly sorted until it is fully sorted.
Changes the array in place.
What you need to know
Inefficient for large data sets, but can be faster for than other algorithms for small ones.
Although it has an
O(n^2), in practice it slightly less since its comparison scheme only requires checking place if its smaller than its neighbor.
Time Complexity
Best Case:
O(n)Average Case:
O(n^2)Worst Case:
O(n^2)
Space Complexity
Worst Case:
O(n)
Visualization
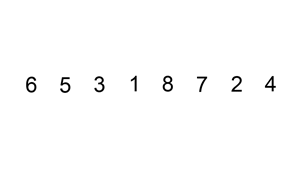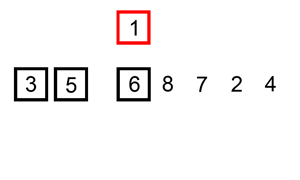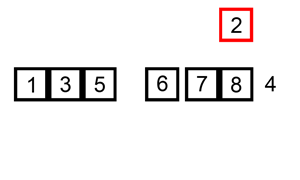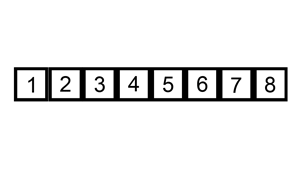
(source: Wikipedia, Insertion Sort)
Merge Sort
Definition
A divide and conquer algorithm.
Recursively divides entire array by half into subsets until the subset is one, the base case.
Once the base case is reached results are returned and sorted ascending left to right.
Recursive calls are returned and the sorts double in size until the entire array is sorted.
What you need to know
This is one of the fundamental sorting algorithms.
Know that it divides all the data into as small possible sets then compares them.
Time Complexity
Worst Case:
O(n log n)Average Case:
O(n log n)Best Case:
O(n)
Space Complexity
Worst Case:
O(1)
Visualization
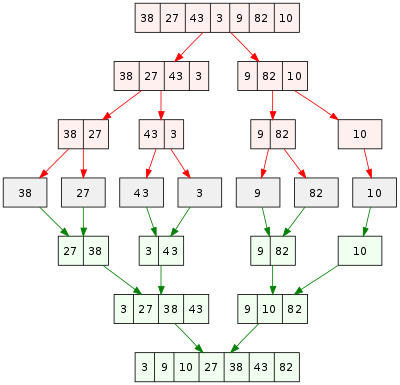
(source: Wikipedia, Merge Sort)
Quicksort
Definition
A divide and conquer algorithm
Partitions entire data set in half by selecting a random pivot element and putting all smaller elements to the left of the element and larger ones to the right.
It repeats this process on the left side until it is comparing only two elements at which point the left side is sorted.
When the left side is finished sorting it performs the same operation on the right side.
Computer architecture favors the quicksort process.
Changes the array in place.
What you need to know
While it has the same Big O as (or worse in some cases) many other sorting algorithms it is often faster in practice than many other sorting algorithms, such as merge sort.
Time Complexity
Worst Case:
O(n^2)Average Case:
O(n log n)Best Case:
O(n log n)
Space Complexity
Worst Case:
O(log n)
Visualization

(source: Wikipedia, Quicksort)
Merge Sort Vs. Quicksort
Quicksort is likely faster in practice, but merge sort is faster on paper.
Merge Sort divides the set into the smallest possible groups immediately then reconstructs the incrementally as it sorts the groupings.
Quicksort continually partitions the data set by a pivot, until the set is recursively sorted.
Additional Resources
Khan Academy's Algorithm Course
What is ARIA and when should you use it?
Answer
ARIA stands for "Accessible Rich Internet Applications", and is a technical specification created by the World Wide Web Consortium (W3C). Better known as WAI-ARIA, it provides additional HTML attributes in the development of web applications to offer people who use assistive technologies (AT) a more robust and interoperable experience with dynamic components. By providing the component's role, name, and state, AT users can better understand how to interact with the component. WAI-ARIA should only be used when an HTML element equivalent is not available or lacks full browser or AT support. WAI-ARIA's semantic markup coupled with JavaScript works to provide an understandable and interactive experience for people who use AT. An example using ARIA:
Credit: W3C's ARIA 1.1 Combobox with Grid Popup Example
Don't forget:
Accessible Rich Internet Applications
Benefits people who use assistive technologies (AT)
Provides role, name, and state
Semantic HTML coupled with JavaScript
Additional links
What is the minimum recommended ratio of contrast between foreground text and background to comply with WCAG? Why does this matter?
Answer
4.5:1 is the calculated contrast ratio between foreground text and background that is recommended by the Web Content Accessibiity Guidelines (WCAG) success criteria (SC) 1.4.3: Contrast (Minimum). This SC was written by the World Wide Web Consortium (W3C) to ensure that people with low vision or color deficiencies are able to read (perceive) important content on a web page. It goes beyond color choices to ensure text stands out on the background it's placed on.
Don't forget:
At least 4.5:1 contrast ratio between foreground text and background
Benefits people with low vision or color deficiencies
Additional links
What are some of the tools available to test the accessibility of a website or web application?
Answer
There are multiple tools that can help you to find for accessibility issues in your website or application. Check for issues in your website:
Lighthouse from Google, it provides an option for accessibility testing, it will check for the compliance of different accessibility standards and give you an score with details on the different issues
Axe Coconut from DequeLabs, it is a Chrome extension that adds a tab in the Developer tools, it will check for accessibility issues and it will classify them by severity and suggest possible solutions
Check for issues in your code: * Jest Axe, you can add unit tests for accessibility * React Axe, test your React application with the axe-core accessibility testing library. Results will show in the Chrome DevTools console. * eslint-plugin-jsx-a11y, pairing this plugin with an editor lint plugin, you can bake accessibility standards into your application in real-time. Check for individual issues: * Color Contrast checkers * Use a screen reader * Use only keyboard to navigate your site
Don't forget:
None of the tools will replace manual testing
Mention of different ways to test accessibility
Additional links
What is the Accessibility Tree?
Answer
The Accessibility Tree is a structure produced by the browser's Accessibility APIs which provides accessibility information to assistive technologies such as screen readers. It runs parallel to the DOM and is similar to the DOM API, but with much fewer nodes, because a lot of that information is only useful for visual presentation. By writing semantic HTML we can take advantage of this process in creating an accessible experience for our users.
Don't forget:
Tree structure exposing information to assistive technologies
Runs parallel to the DOM
Semantic HTML is essential in creating accessible experiences
Additional links
What is the purpose of the alt attribute on images?
alt attribute on images?Answer
The alt attribute provides alternative information for an image if a user cannot view it. The alt attribute should be used to describe any images except those which only serve a decorative purpose, in which case it should be left empty.
Don't forget:
Decorative images should have an empty
altattribute.Web crawlers use
alttags to understand image content, so they are considered important for Search Engine Optimization (SEO).Put the
.at the end ofalttag to improve accessibility.
Additional links
What are defer and async attributes on a <script> tag?
defer and async attributes on a <script> tag?Answer
If neither attribute is present, the script is downloaded and executed synchronously, and will halt parsing of the document until it has finished executing (default behavior). Scripts are downloaded and executed in the order they are encountered.
The defer attribute downloads the script while the document is still parsing but waits until the document has finished parsing before executing it, equivalent to executing inside a DOMContentLoaded event listener. defer scripts will execute in order.
The async attribute downloads the script during parsing the document but will pause the parser to execute the script before it has fully finished parsing. async scripts will not necessarily execute in order.
Note: both attributes must only be used if the script has a src attribute (i.e. not an inline script).
Don't forget:
Placing a
deferscript in the<head>allows the browser to download the script while the page is still parsing, and is therefore a better option than placing the script before the end of the body.If the scripts rely on each other, use
defer.If the script is independent, use
async.Use
deferif the DOM must be ready and the contents are not placed within aDOMContentLoadedlistener.
Additional links
What is an async function?
async function?Answer
An async function is a function that allows you to pause the function's execution while it waits for ( await s) a promise to resolve. It's an abstraction on top of the Promise API that makes asynchronous operations look like they're synchronous.
async functions automatically return a Promise object. Whatever you return from the async function will be the promise's resolution. If instead you throw from the body of an async function, that will be how your async function rejects the promise it returns.
Most importantly, async functions are able to use the await keyword in their function body, which pauses the function until the operation after the await completes, and allows it to return that operation's result to a variable synchronously.
Don't forget:
asyncfunctions are just syntactic sugar on top of Promises.They make asynchronous operations look like synchronous operations in your function.
They implicitly return a promise which resolves to whatever your
asyncfunction returns, and reject to whatever yourasyncfunctionthrows.
Additional links
Create a function batches that returns the maximum number of whole batches that can be cooked from a recipe.
batches that returns the maximum number of whole batches that can be cooked from a recipe.Answer
We must have all ingredients of the recipe available, and in quantities that are more than or equal to the number of units required. If just one of the ingredients is not available or lower than needed, we cannot make a single batch.
Use Object.keys() to return the ingredients of the recipe as an array, then use Array.prototype.map() to map each ingredient to the ratio of available units to the amount required by the recipe. If one of the ingredients required by the recipe is not available at all, the ratio will evaluate to NaN , so the logical OR operator can be used to fallback to 0 in this case.
Use the spread ... operator to feed the array of all the ingredient ratios into Math.min() to determine the lowest ratio. Passing this entire result into Math.floor() rounds down to return the maximum number of whole batches.
Don't forget:
Additional links
What is CSS BEM?
Answer
The BEM methodology is a naming convention for CSS classes in order to keep CSS more maintainable by defining namespaces to solve scoping issues. BEM stands for Block Element Modifier which is an explanation for its structure. A Block is a standalone component that is reusable across projects and acts as a "namespace" for sub components (Elements). Modifiers are used as flags when a Block or Element is in a certain state or is different in structure or style.
Here is an example with the class names on markup:
In this case, navbar is the Block, navbar__link is an Element that makes no sense outside of the navbar component, and navbar__link--active is a Modifier that indicates a different state for the navbar__link Element.
Since Modifiers are verbose, many opt to use is-* flags instead as modifiers.
These must be chained to the Element and never alone however, or there will be scope issues.
Don't forget:
Alternative solutions to scope issues like CSS-in-JS
Additional links
What is Big O Notation?
Answer
Big O notation is used in Computer Science to describe the time complexity of an algorithm. The best algorithms will execute the fastest and have the simplest complexity.
Algorithms don't always perform the same and may vary based on the data they are supplied. While in some cases they will execute quickly, in other cases they will execute slowly, even with the same number of elements to deal with.
In these examples, the base time is 1 element = 1ms .
O(1)
1000 elements =
1ms
Constant time complexity. No matter how many elements the array has, it will theoretically take (excluding real-world variation) the same amount of time to execute.
O(N)
1000 elements =
1000ms
Linear time complexity. The execution time will increase linearly with the number of elements the array has. If the array has 1000 elements and the function takes 1ms to execute, 7000 elements will take 7ms to execute. This is because the function must iterate through all elements of the array before returning a result.
O([1, N])
1000 elements =
1ms <= x <= 1000ms
The execution time varies depending on the data supplied to the function, it may return very early or very late. The best case here is O(1) and the worst case is O(N).
O(NlogN)
1000 elements ~=
10000ms
Browsers usually implement the quicksort algorithm for the sort() method and the average time complexity of quicksort is O(NlgN). This is very efficient for large collections.
O(N^2)
1000 elements =
1000000ms
The execution time rises quadratically with the number of elements. Usually the result of nesting loops.
O(N!)
1000 elements =
Infinity(practically) ms
The execution time rises extremely fast with even just 1 addition to the array.
Don't forget:
Be wary of nesting loops as execution time increases exponentially.
Additional links
Create a standalone function bind that is functionally equivalent to the method Function.prototype.bind .
bind that is functionally equivalent to the method Function.prototype.bind .Answer
Return a function that accepts an arbitrary number of arguments by gathering them with the rest ... operator. From that function, return the result of calling the fn with Function.prototype.apply to apply the context and the array of arguments to the function.
Don't forget:
Additional links
What is the purpose of cache busting and how can you achieve it?
Answer
Browsers have a cache to temporarily store files on websites so they don't need to be re-downloaded again when switching between pages or reloading the same page. The server is set up to send headers that tell the browser to store the file for a given amount of time. This greatly increases website speed and preserves bandwidth. However, it can cause problems when the website has been changed by developers because the user's cache still references old files. This can either leave them with old functionality or break a website if the cached CSS and JavaScript files are referencing elements that no longer exist, have moved or have been renamed. Cache busting is the process of forcing the browser to download the new files. This is done by naming the file something different to the old file. A common technique to force the browser to re-download the file is to append a query string to the end of the file.
src="js/script.js"=>src="js/script.js?v=2"
The browser considers it a different file but prevents the need to change the file name.
Don't forget:
Additional links
How can you avoid callback hells?
Answer
Refactoring the functions to return promises and using async/await is usually the best option. Instead of supplying the functions with callbacks that cause deep nesting, they return a promise that can be await ed and will be resolved once the data has arrived, allowing the next line of code to be evaluated in a sync-like fashion.
The above code can be restructured like so:
There are lots of ways to solve the issue of callback hells:
Modularization: break callbacks into independent functions
Use a control flow library, like async
Use generators with Promises
Use async/await (from v7 on)
Don't forget:
As an efficient JavaScript developer, you have to avoid the constantly growing indentation level, produce clean and readable code and be able to handle complex flows.
Additional links
What is the purpose of callback function as an argument of setState ?
setState ?Answer
The callback function is invoked when setState has finished and the component gets rendered. Since setState is asynchronous, the callback function is used for any post action.
Don't forget:
The callback function is invoked after
setStatefinishes and is used for any post action.It is recommended to use lifecycle method rather this callback function.
Additional links
Which is the preferred option between callback refs and findDOMNode()?
Answer
Callback refs are preferred over the findDOMNode() API, due to the fact that findDOMNode() prevents certain improvements in React in the future.
Don't forget:
Callback refs are preferred over
findDOMNode().
Additional links
What is a callback? Can you show an example using one?
Answer
Callbacks are functions passed as an argument to another function to be executed once an event has occurred or a certain task is complete, often used in asynchronous code. Callback functions are invoked later by a piece of code but can be declared on initialization without being invoked. As an example, event listeners are asynchronous callbacks that are only executed when a specific event occurs.
However, callbacks can also be synchronous. The following map function takes a callback function that is invoked synchronously for each iteration of the loop (array element).
Don't forget:
Functions are first-class objects in JavaScript
Callbacks vs Promises
Additional links
What is the children prop?
children prop?Answer
children is part of the props object passed to components that allows components to be passed as data to other components, providing the ability to compose components cleanly. There are a number of methods available in the React API to work with this prop, such as React. Children.map , React. Children.forEach , React. Children.count , React.Children.only and React. Children.toArray . A simple usage example of the children prop is as follows:
Don't forget:
Children is a prop that allows components to be passed as data to other components.
The React API provides methods to work with this prop.
Additional links
Why does React use className instead of class like in HTML?
className instead of class like in HTML?Answer
React's philosophy in the beginning was to align with the browser DOM API rather than HTML, since that more closely represents how elements are created. Setting a class on an element meant using the className API:
Additionally, before ES5, reserved words could not be used in objects:
In IE8, this will throw an error. In modern environments, destructuring will throw an error if trying to assign to a variable:
However, class can be used as a prop without problems, as seen in other libraries like Preact. React currently allows you to use class , but will throw a warning and convert it to className under the hood. There is currently an open thread (as of January 2019) discussing changing className to class to reduce confusion.
Don't forget:
Additional links
How do you clone an object in JavaScript?
Answer
Using the object spread operator ... , the object's own enumerable properties can be copied into the new object. This creates a shallow clone of the object.
With this technique, prototypes are ignored. In addition, nested objects are not cloned, but rather their references get copied, so nested objects still refer to the same objects as the original. Deep-cloning is much more complex in order to effectively clone any type of object (Date, RegExp, Function, Set, etc) that may be nested within the object. Other alternatives include:
JSON.parse(JSON.stringify(obj))can be used to deep-clone a simple object, but it is CPU-intensive and only accepts valid JSON (therefore it strips functions and does not allow circular references).Object.assign({}, obj)is another alternative.Object.keys(obj).reduce((acc, key) => (acc[key] = obj[key], acc), {})is another more verbose alternative that shows the concept in greater depth.
Don't forget:
JavaScript passes objects by reference, meaning that nested objects get their references copied, instead of their values.
The same method can be used to merge two objects.
Additional links
What is a closure? Can you give a useful example of one?
Answer
A closure is a function defined inside another function and has access to its lexical scope even when it is executing outside its lexical scope. The closure has access to variables in three scopes:
Variables declared in its own scope
Variables declared in the scope of the parent function
Variables declared in the global scope
In JavaScript, all functions are closures because they have access to the outer scope, but most functions don't utilise the usefulness of closures: the persistence of state. Closures are also sometimes called stateful functions because of this. In addition, closures are the only way to store private data that can't be accessed from the outside in JavaScript. They are the key to the UMD (Universal Module Definition) pattern, which is frequently used in libraries that only expose a public API but keep the implementation details private, preventing name collisions with other libraries or the user's own code.
Don't forget:
Closures are useful because they let you associate data with a function that operates on that data.
A closure can substitute an object with only a single method.
Closures can be used to emulate private properties and methods.
Additional links
How do you compare two objects in JavaScript?
Answer
Even though two different objects can have the same properties with equal values, they are not considered equal when compared using == or === . This is because they are being compared by their reference (location in memory), unlike primitive values which are compared by value.
In order to test if two objects are equal in structure, a helper function is required. It will iterate through the own properties of each object to test if they have the same values, including nested objects. Optionally, the prototypes of the objects may also be tested for equivalence by passing true as the 3rd argument.
Note: this technique does not attempt to test equivalence of data structures other than plain objects, arrays, functions, dates and primitive values.
Don't forget:
Primitives like strings and numbers are compared by their value
Objects on the other hand are compared by their reference (location in memory)
Additional links
What is context?
Answer
Context provides a way to pass data through the component tree without having to pass props down manually at every level. For example, authenticated user, locale preference, UI theme need to be accessed in the application by many components.
Don't forget:
Context provides a way to pass data through a tree of React components, without having to manually pass props.
Context is designed to share data that is considered global for a tree of React components.
Additional links
What is CORS?
Answer
Cross-Origin Resource Sharing or CORS is a mechanism that uses additional HTTP headers to grant a browser permission to access resources from a server at an origin different from the website origin.
An example of a cross-origin request is a web application served from http://mydomain.com that uses AJAX to make a request for http://yourdomain.com .
For security reasons, browsers restrict cross-origin HTTP requests initiated by JavaScript. XMLHttpRequest and fetch follow the same-origin policy, meaning a web application using those APIs can only request HTTP resources from the same origin the application was accessed, unless the response from the other origin includes the correct CORS headers.
Don't forget:
CORS behavior is not an error, it's a security mechanism to protect users.
CORS is designed to prevent a malicious website that a user may unintentionally visit from making a request to a legitimate website to read their personal data or perform actions against their will.
Additional links
Describe the layout of the CSS Box Model and briefly describe each component.
Answer
Content : The inner-most part of the box filled with content, such as text, an image, or video player. It has the dimensions content-box width and content-box height .
Padding : The transparent area surrounding the content. It has dimensions padding-box width and padding-box height .
Border : The area surrounding the padding (if any) and content. It has dimensions border-box width and border-box height .
Margin: The transparent outer-most layer that surrounds the border. It separates the element from other elements in the DOM. It has dimensions margin-box width and margin-box height .
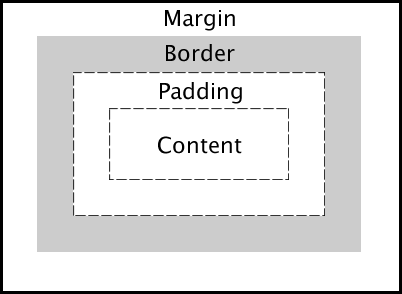
alt text
Don't forget:
This is a very common question asked during front-end interviews and while it may seem easy, it is critical you know it well!
Shows a solid understanding of spacing and the DOM
Additional links
What are the advantages of using CSS preprocessors?
Answer
CSS preprocessors add useful functionality that native CSS does not have, and generally make CSS neater and more maintainable by enabling DRY (Don't Repeat Yourself) principles. Their terse syntax for nested selectors cuts down on repeated code. They provide variables for consistent theming (however, CSS variables have largely replaced this functionality) and additional tools like color functions ( lighten , darken , transparentize , etc), mixins, and loops that make CSS more like a real programming language and gives the developer more power to generate complex CSS.
Don't forget:
They allow us to write more maintainable and scalable CSS
Some disadvantages of using CSS preprocessors (setup, re-compilation time can be slow etc.)
Additional links
What is the difference between '+' and '~' sibling selectors?.
Answer
The General Sibling Selector ~ selects all elements that are siblings of a specified element.
The following example selects all <p> elements that are siblings of <div> elements:
The Adjacent Sibling Selector + selects all elements that are the adjacent siblings of a specified element.
The following example will select all <p> elements that are placed immediately after <div> elements:
Don't forget:
Additional links
Can you describe how CSS specificity works?
Answer
Assuming the browser has already determined the set of rules for an element, each rule is assigned a matrix of values, which correspond to the following from highest to lowest specificity:
Inline rules (binary - 1 or 0)
Number of id selectors
Number of class, pseudo-class and attribute selectors
Number of tags and pseudo-element selectors
When two selectors are compared, the comparison is made on a per-column basis (e.g. an id selector will always be higher than any amount of class selectors, as ids have higher specificity than classes). In cases of equal specificity between multiple rules, the rules that comes last in the page's style sheet is deemed more specific and therefore applied to the element.
Don't forget:
Specificity matrix: [inline, id, class/pseudo-class/attribute, tag/pseudo-element]
In cases of equal specificity, last rule is applied
Additional links
What is debouncing?
Answer
Debouncing is a process to add some delay before executing a function. It is commonly used with DOM event listeners to improve the performance of page. It is a technique which allow us to "group" multiple sequential calls in a single one. A raw DOM event listeners can easily trigger 20+ events per second. A debounced function will only be called once the delay has passed.
Don't forget:
Common use case is to make API call only when user is finished typing while searching.
Additional links
What is the DOM?
Answer
The DOM (Document Object Model) is a cross-platform API that treats HTML and XML documents as a tree structure consisting of nodes. These nodes (such as elements and text nodes) are objects that can be programmatically manipulated and any visible changes made to them are reflected live in the document. In a browser, this API is available to JavaScript where DOM nodes can be manipulated to change their styles, contents, placement in the document, or interacted with through event listeners.
Don't forget:
The DOM was designed to be independent of any particular programming language, making the structural representation of the document available from a single, consistent API.
The DOM is constructed progressively in the browser as a page loads, which is why scripts are often placed at the bottom of a page, in the
<head>with adeferattribute, or inside aDOMContentLoadedevent listener. Scripts that manipulate DOM nodes should be run after the DOM has been constructed to avoid errors.document.getElementById()anddocument.querySelector()are common functions for selecting DOM nodes.Setting the
innerHTMLproperty to a new value runs the string through the HTML parser, offering an easy way to append dynamic HTML content to a node.
Additional links
What is the difference between the equality operators == and === ?
== and === ?Answer
Triple equals ( === ) checks for strict equality, which means both the type and value must be the same. Double equals ( == ) on the other hand first performs type coercion so that both operands are of the same type and then applies strict comparison.
Don't forget:
Whenever possible, use triple equals to test equality because loose equality
==can have unintuitive results.Type coercion means the values are converted into the same type.
Mention of falsy values and their comparison.
Additional links
What is the difference between an element and a component in React?
Answer
An element is a plain JavaScript object that represents a DOM node or component. Elements are pure and never mutated, and are cheap to create. A component is a function or class. Components can have state and take props as input and return an element tree as output (although they can represent generic containers or wrappers and don't necessarily have to emit DOM). Components can initiate side effects in lifecycle methods (e.g. AJAX requests, DOM mutations, interfacing with 3rd party libraries) and may be expensive to create.
Last updated