
Rest Architecture
Introduction
API Browser Quick Guide
It can make your life easier if you use some kind of API browser application to explore the API when diving into this documentation.
We recommend to use the free Postman browser plugin.
For easy onboarding take a look at our Explore the API using Postman Quick-Guide.
A hypermedia API provides an entry point to the API, which contains hyperlinks the clients can follow. Just like a human user of a regular website, who knows the initial URL of a website and then follows hyperlinks to navigate through the site. This has the advantage that the client only needs to understand how to detect and follow links. The URLs (apart from the inital entry point) and other details of the API can change without breaking the client.
The entry point to the Plone RESTful API is the portal root. The client can ask for a REST API response by setting the 'Accept' HTTP header to 'application/json':
http
curl
httpie
python-requests
GET /plone HTTP/1.1
Accept: application/json
Authorization: Basic YWRtaW46c2VjcmV0This uses so-called ‘content negotiation’
The server will then respond with the portal root in the JSON format:
@id is a unique identifier for resources (IRIs). The @id property can be used to navigate through the web API by following the links.
@type sets the data type of a node or typed value
items is a list that contains all objects within that resource.
A client application can “follow” the links (by calling the @id property) to other resources. This allows to build a losely coupled client that does not break if some of the URLs change, only the entry point of the entire API (in our case the portal root) needs to be known in advance.
Another example, this time showing a request and response for a document. Click on the buttons below to show the different syntaxes for the request.
http
curl
httpie
python-requests
And so on, see
Explore the API using Postman
To discover the API interactively, using Postman is recommended.
Note
The Chrome-Extension version of Postman is deprecated and it is recommended to use the native app available instead.
Configuration
To easily follow links returned by request based on the API,
go to the menu under the wrench icon on the top right
choose Settings
activate the option Retain headers on clicking on links by selecting ON:
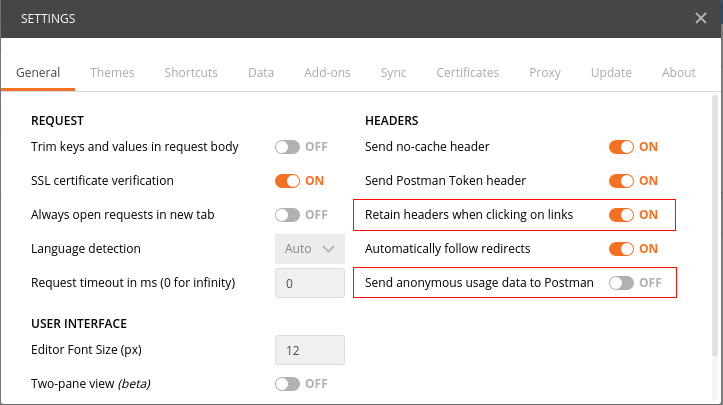
This option makes sure, once a HTTP-Header is configured, it will be reused during following requests , if these are initiated by clicking on links resulting from the initial request. This way navigating the structure using the API becomes a snap.
The option Send anonymous usage data to Postman should be deactivated by setting to OFF.
Usage
Choose the suitable HTTP Verb to be used for your request. This can be selected using the Postman HTTP Verb -> GET drop-down menu.
Enter the Object URL of the object that should be the target of a request into the URL field right to the HTTP Verb:

Now set the appropriate HTTP headers.
The Authorization Header for the authentication related to the right user
The Accept Header to initiate the right behaviour by the API related to this Request.
To set the Authorization Header, there is a reserved tab, that is responsible to generate the final Header based on the authentication method and username + password.
You have to select
in the drop-down menu Basic Auth -> the term Basic Auth as the authentication method
A valid existing user with appropriate permissions
After providing these parameters you can create the resulting Authorization Header and insert it into the prepared request by clicking on Preview Request.
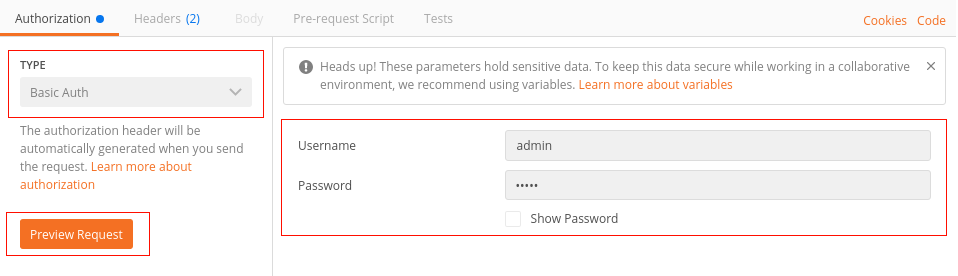
Under the Headers tab you now need to insert in the Accept Header application/json` header as well:

The request is now ready and can be send by clicking on Send button.
The Response of the server is now displayed below the Request. You can easily follow the links on the @id attributes by clicking on them. For every link Postman has prepared another request sharing the same headers that can be send again by licking on the Send button.
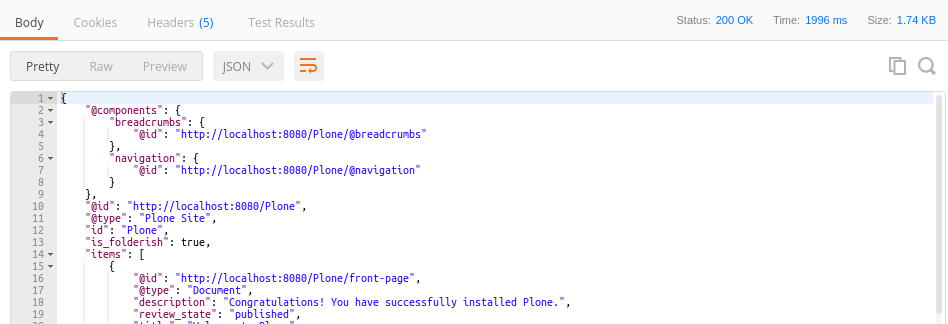
Conclusion
You can now explore the whole stucture of your application easily via the API using GET requests.
Content Manipulation
plone.restapi does not only expose content objects via a RESTful API. The API consumer can create, read, update, and delete a content object. Those operations can be mapped to the HTTP verbs POST (Create), GET (Read), PUT (Update) and DELETE (Delete).
Manipulating resources across the network by using HTTP as an application protocol is one of core principles of the REST architectural pattern. This allows us to interact with a specific resource in a standardized way:
POST
/folder
Creates a new document within the folder
GET
/folder/{document-id}
Request the current state of the document
PATCH
/folder/{document-id}
Update the document details
DELETE
/folder/{document-id}
Remove the document
Creating a Resource with POST
To create a new resource, we send a POST request to the resource container. If we want to create a new document within an existing folder, we send a POST request to that folder:
http
curl
httpie
python-requests
By setting the ‘Accept’ header, we tell the server that we would like to receive the response in the ‘application/json’ representation format.
The ‘Content-Type’ header indicates that the body uses the ‘application/json’ format.
The request body contains the minimal necessary information needed to create a document (the type and the title). You could set other properties, like “description” here as well.
A special property during content creation is “UID”, as it requires the user to have the Manage Portal permission to set it. Without the permission, the request will fail as Unauthorized.
Successful Response (201 Created)
If a resource has been created, the server responds with the 201 Created status code. The ‘Location’ header contains the URL of the newly created resource and the resource representation in the payload:
Unsuccessful Response (400 Bad Request)
If the resource could not be created, for instance because the title was missing in the request, the server responds with 400 Bad Request:
The response body can contain information about why the request failed.
Unsuccessful Response (500 Internal Server Error)
If the server can not properly process a request, it responds with 500 Internal Server Error:
The response body can contain further information such as an error trace or a link to the documentation.
Possible POST Responses
Possible server reponses for a POST request are:
201 Created (Resource has been created successfully)
400 Bad Request (malformed request to the service)
500 Internal Server Error (server fault, can not recover internally)
POST Implementation
A pseudo-code example of the POST implementation on the server:
TODO: Link to the real implementation… [
Reading a Resource with GET
After a successful POST, we can access the resource by sending a GET request to the resource URL:
http
curl
httpie
python-requests
Successful Response (200 OK)
If a resource has been retrieved successfully, the server responds with 200 OK:
For folderish types, their childrens are automatically included in the response as items. To disable the inclusion, add the GET parameter include_items=false to the URL.
By default only basic metadata is included. To include additional metadata, you can specify the names of the properties with the metadata_fields parameter. See also Retrieving additional metadata.
The following example additionaly retrieves the UID and Creator:
http
curl
httpie
python-requests
Note
For folderish types, collections or search results, the results will be batched if the size of the resultset exceeds the batch size. See Batching for more details on how to work with batched results.
Unsuccessful response (404 Not Found)
If a resource could not be found, the server will respond with 404 Not Found:
GET Implementation
A pseudo-code example of the GET implementation on the server:
You can find implementation details in the plone.restapi.services.content.add.FolderPost class
GET Responses
Possible server reponses for a GET request are:
Updating a Resource with PATCH
To update an existing resource we send a PATCH request to the server. PATCH allows to provide just a subset of the resource (the values you actually want to change).
If you send the value null for a field, the field’s content will be deleted and the missing_value defined for the field in the schema will be set. Note that this is not possible if the field is required, and it only works for Dexterity types, not Archetypes:
http
curl
httpie
python-requests
Successful Response (204 No Content)
A successful response to a PATCH request will be indicated by a 204 No Content response by default:
Successful Response (200 OK)
You can get the object representation by adding a Prefer header with a value of return=representation to the PATCH request. In this case, the response will be a 200 OK:
http
curl
httpie
python-requests
See for full specs the RFC 5789: PATCH Method for HTTP
Replacing a Resource with PUT
Note
PUT is not implemented yet.
To replace an existing resource we send a PUT request to the server:
TODO: Add example.
In accordance with the HTTP specification, a successful PUT will not create a new resource or produce a new URL.
PUT expects the entire resource representation to be supplied to the server, rather than just changes to the resource state. This is usually not a problem since the consumer application requested the resource representation before a PUT anyways.
When the PUT request is accepted and processed by the service, the consumer will receive a 204 No Content response (200 OK would be a valid alternative).
Successful Update (204 No Content)
When a resource has been updated successfully, the server sends a 204 No Content response:
TODO: Add example.
Unsuccessful Update (409 Conflict)
Sometimes requests fail due to incompatible changes. The response body includes additional information about the problem.
TODO: Add example.
PUT Implementation
A pseudo-code example of the PUT implementation on the server:
TODO: Link to the real implementation…
PUT Responses
Possible server reponses for a PUT request are:
POST vs. PUT
Difference between POST and PUT:
Use POST to create a resource identified by a service-generated URI
Use POST to append a resource to a collection identified by a service-generated URI
Use PUT to overwrite a resource
This follows RFC 7231: HTTP 1.1: PUT Method.
Removing a Resource with DELETE
We can delete an existing resource by sending a DELETE request:
http
curl
httpie
python-requests
A successful response will be indicated by a 204 No Content response:
DELETE Implementation
A pseudo-code example of the DELETE implementation on the server:
TODO: Link to the real implementation…
DELETE Responses
Possible responses to a delete request are:
404 Not Found (if the resource does not exist)
405 Method Not Allowed (if deleting the resource is not allowed)
Reordering sub resources
The resources contained within a resource can be reordered using the ordering key using a PATCH request on the container.
Use the obj_id subkey to specify which resource to reorder. The subkey delta can be ‘top’, ‘bottom’, or a negative or positive integer for moving up or down.
Reordering resources within a subset of resources can be done using the subset_ids subkey.
A response 400 BadRequest with a message ‘Client/server ordering mismatch’ will be returned if the value is not in the same order as serverside.
A response 400 BadRequest with a message ‘Content ordering is not supported by this resource’ will be returned if the container does not support ordering.
http
curl
httpie
python-requests
To rearrange all items in a folderish context use the sort key.
The on subkey defines the catalog index to be sorted on. The order subkey indicates ‘ascending’ or ‘descending’ order of items.
A response 400 BadRequest with a message ‘Content ordering is not supported by this resource’ will be returned if the container does not support ordering.
http
curl
httpie
python-requests
Conventions
Naming Convention for REST API Resources/Endpoints
Nouns vs Verbs
Rule: Use nouns to represent resources.
Do:
Don’t:
Reason:
RESTful URI should refer to a resource that is a thing (noun) instead of referring to an action (verb) because nouns have properties as verbs do not. The REST architectural principle uses HTTP verbs to interact with resources.
Though, there is an exception to that rule, verbs can be used for specific actions or calculations, .e.g.:
Singluar vs Plural
Rule: Use plural resources.
Do:
Don’t:
Reason:
If you use singular for a collection like resource (e.g. “/user” to retrieve a list of all users) it feels wrong. Mixing singular and plural is confusing (e.g. user “/users” for retrieving users and “/user/21” to retrieve a single user).
Upper vs. Lowercase
Rule: Use lowercase letters in URIs.
Do:
Don’t:
Reason: RFC 3986 defines URIs as case-sensitive except for the scheme and host components. e.g.
Those two URIs are equivalent:
While this one is not equivalent to the two URIs above:
To avoid confusion we always use lowercase letters in URIs.
Naming Convention for attribute names in URIs
Rule: Use hyphens (spinal case) to improve readability of URIs.
Do:
Don’t:
Reason:
Spinal case is better to read and safer to use than camelCase (URLs are case sensitive (RFC3986)). Plone uses spinal case for URL creation (title “My page” becomes “my-page”) and mixed naming conventions in URLs would be confusing (e.g. “/my-folder/@send_url_to_user”). Google recommends spinal-case in URLs for better SEO (https://support.google.com/webmasters/answer/76329).
Discussion:
https://github.com/plone/plone.restapi/issues/194
Naming Convention for attribute names in response body
Rule: Use snake_case to reflect Python best practices.
Do:
Don’t:
Reason:
We map over Python attributes 1:1 no matter if they are snake case (modern Python/Plone, Dexterity) of lowerCamelCase (Zope 2, Archetypes).
Versioning
Versioning APIs does make a lot of sense for public API services. Especially if an API provider needs to ship different versions of the API at the same time. Though, Plone already has a way to version packages and it currently does not make sense for us to expose that information via the API. We will always just ship one version of the API at a time and we are usually in full control over the backend and the frontend.
Last updated