> For the complete documentation index, see [llms.txt](https://bryan-guner.gitbook.io/my-docs/llms.txt). Markdown versions of documentation pages are available by appending `.md` to page URLs; this page is available as [Markdown](https://bryan-guner.gitbook.io/my-docs/ai/pytorch.md).
# Pytorch
**Production Ready**
Transition seamlessly between eager and graph modes with TorchScript, and accelerate the path to production with TorchServe.
**Distributed Training**
Scalable distributed training and performance optimization in research and production is enabled by the torch.distributed backend.
**Robust Ecosystem**
A rich ecosystem of tools and libraries extends PyTorch and supports development in computer vision, NLP and more.
**Cloud Support**
PyTorch is well supported on major cloud platforms, providing frictionless development and easy scaling.
Explore a rich ecosystem of libraries, tools, and more to support development.
### Community
Join the PyTorch developer community to contribute, learn, and get your questions answered.
#### Learn the Basics
Familiarize yourself with PyTorch concepts and modules. Learn how to load data, build deep neural networks, train and save your models in this quickstart guide.
[Get started with PyTorch](https://pytorch.org/tutorials/beginner/basics/intro.html)
#### PyTorch Recipes
Bite-size, ready-to-deploy PyTorch code examples.
[Explore Recipes](https://pytorch.org/tutorials/recipes/recipes_index.html)
#### Examples of PyTorch
A set of examples around pytorch in Vision, Text, Reinforcement Learning, etc.
[Checkout Examples](https://github.com/pytorch/examples)
#### PyTorch Cheat Sheet
Quick overview to essential PyTorch elements.
[Open](https://pytorch.org/tutorials/beginner/ptcheat.html)
#### Tutorials on GitHub
Access PyTorch Tutorials from GitHub.
[Go To GitHub](https://github.com/pytorch/tutorials)
#### Run Tutorials on Google Colab
Learn how to copy tutorial data into Google Drive so that you can run tutorials on Google Colab.
[Open](https://pytorch.org/tutorials/beginner/colab.html)
We’ve added a new feature to tutorials that allows users to open the notebook associated with a tutorial in Google Colab. You may need to copy data to your Google drive account to get the more complex tutorials to work.
In this example, we’ll demonstrate how to change the notebook in Colab to work with the Chatbot Tutorial. To do this, you’ll first need to be logged into Google Drive. (For a full description of how to access data in Colab, you can view their example notebook [here](https://colab.research.google.com/notebooks/io.ipynb#scrollTo=XDg9OBaYqRMd).)
To get started open the [Chatbot Tutorial](https://pytorch.org/tutorials/beginner/chatbot_tutorial.html) in your browser.
At the top of the page click **Run in Google Colab**.
The file will open in Colab.
If you select **Runtime**, and then **Run All**, you’ll get an error as the file can’t be found.
To fix this, we’ll copy the required file into our Google Drive account.
1. Log into Google Drive.
2. In Google Drive, make a folder named **data**, with a subfolder named **cornell**.
3. Visit the Cornell Movie Dialogs Corpus and download the ZIP file.
4. Unzip the file on your local machine.
5. Copy the files **movie\_lines.txt** and **movie\_conversations.txt** to the **data/cornell** folder that you created in Google Drive.
Now we’ll need to edit the file in\_ \_Colab to point to the file on Google Drive.
In Colab, add the following to top of the code section over the line that begins *corpus\_name*:
from google.colab import drive drive.mount('/content/gdrive')
Change the two lines that follow:
1. Change the **corpus\_name** value to **“cornell”**.
2. Change the line that begins with **corpus** to this:
corpus = os.path.join("/content/gdrive/My Drive/data", corpus\_name)
We’re now pointing to the file we uploaded to Drive.
Now when you click the **Run cell** button for the code section, you’ll be prompted to authorize Google Drive and you’ll get an authorization code. Paste the code into the prompt in Colab and you should be set.
Rerun the notebook from the **Runtime** / **Run All** menu command and you’ll see it process. (Note that this tutorial takes a long time to run.)
Hopefully this example will give you a good starting point for running some of the more complex tutorials in Colab. As we evolve our use of Colab on the PyTorch tutorials site, we’ll look at ways to make this easier for users.
We’ve added a new feature to tutorials that allows users to open the notebook associated with a tutorial in Google Colab. You may need to copy data to your Google drive account to get the more complex tutorials to work.
In this example, we’ll demonstrate how to change the notebook in Colab to work with the Chatbot Tutorial. To do this, you’ll first need to be logged into Google Drive. (For a full description of how to access data in Colab, you can view their example notebook [here](https://colab.research.google.com/notebooks/io.ipynb#scrollTo=XDg9OBaYqRMd).)
To get started open the [Chatbot Tutorial](https://pytorch.org/tutorials/beginner/chatbot_tutorial.html) in your browser.
At the top of the page click **Run in Google Colab**.
The file will open in Colab.
If you select **Runtime**, and then **Run All**, you’ll get an error as the file can’t be found.
To fix this, we’ll copy the required file into our Google Drive account.
1. Log into Google Drive.
2. In Google Drive, make a folder named **data**, with a subfolder named **cornell**.
3. Visit the Cornell Movie Dialogs Corpus and download the ZIP file.
4. Unzip the file on your local machine.
5. Copy the files **movie\_lines.txt** and **movie\_conversations.txt** to the **data/cornell** folder that you created in Google Drive.
Now we’ll need to edit the file in\_ \_Colab to point to the file on Google Drive.
In Colab, add the following to top of the code section over the line that begins *corpus\_name*:
from google.colab import drive drive.mount('/content/gdrive')
Change the two lines that follow:
1. Change the **corpus\_name** value to **“cornell”**.
2. Change the line that begins with **corpus** to this:
corpus = os.path.join("/content/gdrive/My Drive/data", corpus\_name)
We’re now pointing to the file we uploaded to Drive.
Now when you click the **Run cell** button for the code section, you’ll be prompted to authorize Google Drive and you’ll get an authorization code. Paste the code into the prompt in Colab and you should be set.
Rerun the notebook from the **Runtime** / **Run All** menu command and you’ll see it process. (Note that this tutorial takes a long time to run.)
Hopefully this example will give you a good starting point for running some of the more complex tutorials in Colab. As we evolve our use of Colab on the PyTorch tutorials site, we’ll look at ways to make this easier for users.
Note
Click [here](https://pytorch.org/tutorials/beginner/audio_feature_extractions_tutorial.html#sphx-glr-download-beginner-audio-feature-extractions-tutorial-py) to download the full example code
`torchaudio` implements feature extractions commonly used in the audio domain. They are available in `torchaudio.functional` and `torchaudio.transforms`.
`functional` implements features as standalone functions. They are stateless.
`transforms` implements features as objects, using implementations from `functional` and `torch.nn.Module`. Because all transforms are subclasses of `torch.nn.Module`, they can be serialized using TorchScript.
For the complete list of available features, please refer to the documentation. In this tutorial, we will look into converting between the time domain and frequency domain (`Spectrogram`, `GriffinLim`, `MelSpectrogram`).
\# When running this tutorial in Google Colab, install the required packages # with the following. # !pip install torchaudio librosa
import torch import torchaudio import torchaudio.functional as F import torchaudio.transforms as T
print(torch.\_\_version\_\_) print(torchaudio.\_\_version\_\_)
Out:
1.10.0+cu102 0.10.0+cu102
### Preparing data and utility functions (skip this section)
\#@title Prepare data and utility functions. {display-mode: "form"} #@markdown #@markdown You do not need to look into this cell. #@markdown Just execute once and you are good to go. #@markdown #@markdown In this tutorial, we will use a speech data from \[VOiCES dataset]\(), which is licensed under Creative Commos BY 4.0.
\#------------------------------------------------------------------------------- # Preparation of data and helper functions. #-------------------------------------------------------------------------------
import os import requests
import librosa import matplotlib.pyplot as plt from IPython.display import Audio, display
\_SAMPLE\_DIR = "\_sample\_data"
SAMPLE\_WAV\_SPEECH\_URL = "" SAMPLE\_WAV\_SPEECH\_PATH = os.path.join(\_SAMPLE\_DIR, "speech.wav")
os.makedirs(\_SAMPLE\_DIR, exist\_ok=True)
def \_fetch\_data(): uri = \[ (SAMPLE\_WAV\_SPEECH\_URL, SAMPLE\_WAV\_SPEECH\_PATH), ] for url, path in uri: with open(path, 'wb') as file\_: file\_.write(requests.get(url).content)
\_fetch\_data()
def \_get\_sample(path, resample=None): effects = \[ \["remix", "1"] ] if resample: effects.extend(\[ \["lowpass", f"{resample // 2}"], \["rate", f'{resample}'], ]) return torchaudio.sox\_effects.apply\_effects\_file(path, effects=effects)
def get\_speech\_sample(\*, resample=None): return \_get\_sample(SAMPLE\_WAV\_SPEECH\_PATH, resample=resample)
def print\_stats(waveform, sample\_rate=None, src=None): if src: print("-" \* 10) print("Source:", src) print("-" \* 10) if sample\_rate: print("Sample Rate:", sample\_rate) print("Shape:", tuple(waveform.shape)) print("Dtype:", waveform.dtype) print(f" - Max: {waveform.max().item():6.3f}") print(f" - Min: {waveform.min().item():6.3f}") print(f" - Mean: {waveform.mean().item():6.3f}") print(f" - Std Dev: {waveform.std().item():6.3f}") print() print(waveform) print()
def plot\_spectrogram(spec, title=None, ylabel='freq\_bin', aspect='auto', xmax=None): fig, axs = plt.subplots(1, 1) axs.set\_title(title or 'Spectrogram (db)') axs.set\_ylabel(ylabel) axs.set\_xlabel('frame') im = axs.imshow(librosa.power\_to\_db(spec), origin='lower', aspect=aspect) if xmax: axs.set\_xlim((0, xmax)) fig.colorbar(im, ax=axs) plt.show(block=False)
def plot\_waveform(waveform, sample\_rate, title="Waveform", xlim=None, ylim=None): waveform = waveform.numpy()
num\_channels, num\_frames = waveform.shape time\_axis = torch.arange(0, num\_frames) / sample\_rate
figure, axes = plt.subplots(num\_channels, 1) if num\_channels == 1: axes = \[axes] for c in range(num\_channels): axes\[c].plot(time\_axis, waveform\[c], linewidth=1) axes\[c].grid(True) if num\_channels > 1: axes\[c].set\_ylabel(f'Channel {c+1}') if xlim: axes\[c].set\_xlim(xlim) if ylim: axes\[c].set\_ylim(ylim) figure.suptitle(title) plt.show(block=False)
def play\_audio(waveform, sample\_rate): waveform = waveform.numpy()
num\_channels, num\_frames = waveform.shape if num\_channels == 1: display(Audio(waveform\[0], rate=sample\_rate)) elif num\_channels == 2: display(Audio((waveform\[0], waveform\[1]), rate=sample\_rate)) else: raise ValueError("Waveform with more than 2 channels are not supported.")
def plot\_mel\_fbank(fbank, title=None): fig, axs = plt.subplots(1, 1) axs.set\_title(title or 'Filter bank') axs.imshow(fbank, aspect='auto') axs.set\_ylabel('frequency bin') axs.set\_xlabel('mel bin') plt.show(block=False)
def plot\_pitch(waveform, sample\_rate, pitch): figure, axis = plt.subplots(1, 1) axis.set\_title("Pitch Feature") axis.grid(True)
end\_time = waveform.shape\[1] / sample\_rate time\_axis = torch.linspace(0, end\_time, waveform.shape\[1]) axis.plot(time\_axis, waveform\[0], linewidth=1, color='gray', alpha=0.3)
axis2 = axis.twinx() time\_axis = torch.linspace(0, end\_time, pitch.shape\[1]) ln2 = axis2.plot( time\_axis, pitch\[0], linewidth=2, label='Pitch', color='green')
axis2.legend(loc=0) plt.show(block=False)
def plot\_kaldi\_pitch(waveform, sample\_rate, pitch, nfcc): figure, axis = plt.subplots(1, 1) axis.set\_title("Kaldi Pitch Feature") axis.grid(True)
end\_time = waveform.shape\[1] / sample\_rate time\_axis = torch.linspace(0, end\_time, waveform.shape\[1]) axis.plot(time\_axis, waveform\[0], linewidth=1, color='gray', alpha=0.3)
time\_axis = torch.linspace(0, end\_time, pitch.shape\[1]) ln1 = axis.plot(time\_axis, pitch\[0], linewidth=2, label='Pitch', color='green') axis.set\_ylim((-1.3, 1.3))
axis2 = axis.twinx() time\_axis = torch.linspace(0, end\_time, nfcc.shape\[1]) ln2 = axis2.plot( time\_axis, nfcc\[0], linewidth=2, label='NFCC', color='blue', linestyle='--')
lns = ln1 + ln2 labels = \[l.get\_label() for l in lns] axis.legend(lns, labels, loc=0) plt.show(block=False)
### Spectrogram
To get the frequency make-up of an audio signal as it varies with time, you can use `Spectrogram`.
waveform, sample\_rate = get\_speech\_sample()
n\_fft = 1024 win\_length = None hop\_length = 512
\# define transformation spectrogram = T.Spectrogram( n\_fft=n\_fft, win\_length=win\_length, hop\_length=hop\_length, center=True, pad\_mode="reflect", power=2.0, ) # Perform transformation spec = spectrogram(waveform)
print\_stats(spec) plot\_spectrogram(spec\[0], title='torchaudio')
Out:
Shape: (1, 513, 107) Dtype: torch.float32
* Max: 4000.533
* Min: 0.000
* Mean: 5.726
* Std Dev: 70.301
tensor(\[\[\[7.8743e+00, 4.4462e+00, 5.6781e-01, ..., 2.7694e+01, 8.9546e+00, 4.1289e+00], \[7.1094e+00, 3.2595e+00, 7.3520e-01, ..., 1.7141e+01, 4.4812e+00, 8.0840e-01], \[3.8374e+00, 8.2490e-01, 3.0779e-01, ..., 1.8502e+00, 1.1777e-01, 1.2369e-01], ..., \[3.4708e-07, 1.0604e-05, 1.2395e-05, ..., 7.4090e-06, 8.2063e-07, 1.0176e-05], \[4.7173e-05, 4.4329e-07, 3.9444e-05, ..., 3.0622e-05, 3.9735e-07, 8.1572e-06], \[1.3221e-04, 1.6440e-05, 7.2536e-05, ..., 5.4662e-05, 1.1663e-05, 2.5758e-06]]])
### GriffinLim
To recover a waveform from a spectrogram, you can use `GriffinLim`.
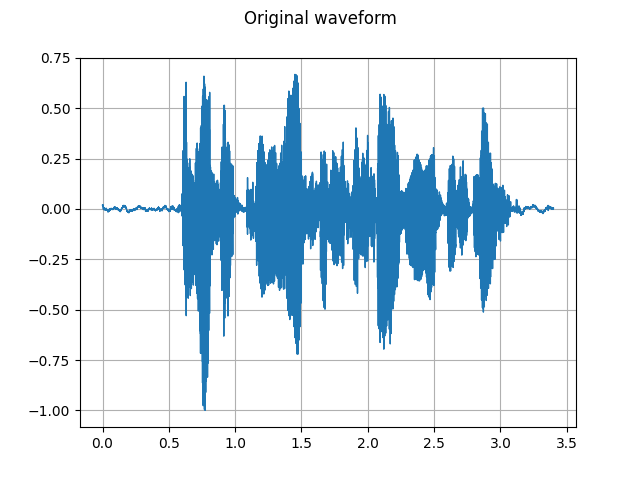
torch.random.manual\_seed(0) waveform, sample\_rate = get\_speech\_sample() plot\_waveform(waveform, sample\_rate, title="Original") play\_audio(waveform, sample\_rate)
n\_fft = 1024 win\_length = None hop\_length = 512
spec = T.Spectrogram( n\_fft=n\_fft, win\_length=win\_length, hop\_length=hop\_length, )(waveform)
griffin\_lim = T.GriffinLim( n\_fft=n\_fft, win\_length=win\_length, hop\_length=hop\_length, ) waveform = griffin\_lim(spec)
plot\_waveform(waveform, sample\_rate, title="Reconstructed") play\_audio(waveform, sample\_rate)
Out:
\ \
### Mel Filter Bank
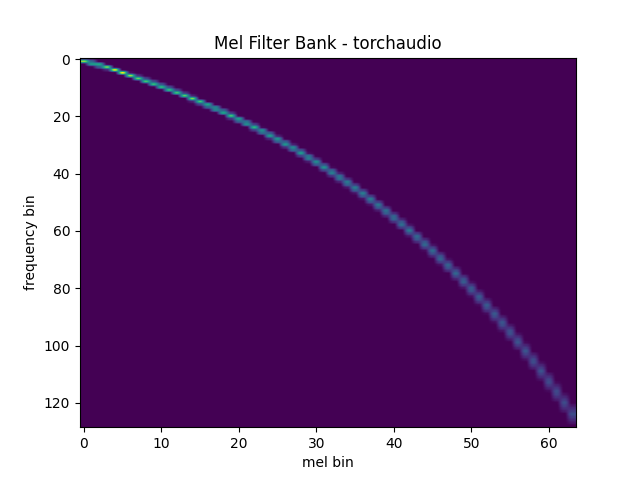
`torchaudio.functional.create_fb_matrix` generates the filter bank for converting frequency bins to mel-scale bins.
Since this function does not require input audio/features, there is no equivalent transform in `torchaudio.transforms`.
n\_fft = 256 n\_mels = 64 sample\_rate = 6000
mel\_filters = F.create\_fb\_matrix( int(n\_fft // 2 + 1), n\_mels=n\_mels, f\_min=0., f\_max=sample\_rate/2., sample\_rate=sample\_rate, norm='slaney' ) plot\_mel\_fbank(mel\_filters, "Mel Filter Bank - torchaudio")
#### Comparison against librosa
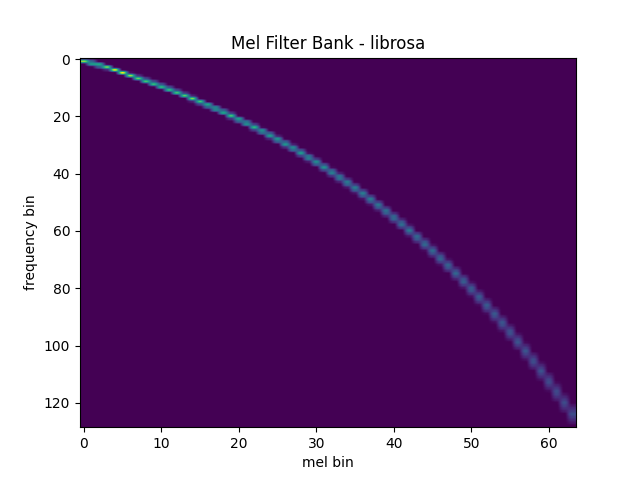
For reference, here is the equivalent way to get the mel filter bank with `librosa`.
mel\_filters\_librosa = librosa.filters.mel( sample\_rate, n\_fft, n\_mels=n\_mels, fmin=0., fmax=sample\_rate/2., norm='slaney', htk=True, ).T
plot\_mel\_fbank(mel\_filters\_librosa, "Mel Filter Bank - librosa")
mse = torch.square(mel\_filters - mel\_filters\_librosa).mean().item() print('Mean Square Difference: ', mse)
Out:
Mean Square Difference: 3.795462323290159e-17
### MelSpectrogram
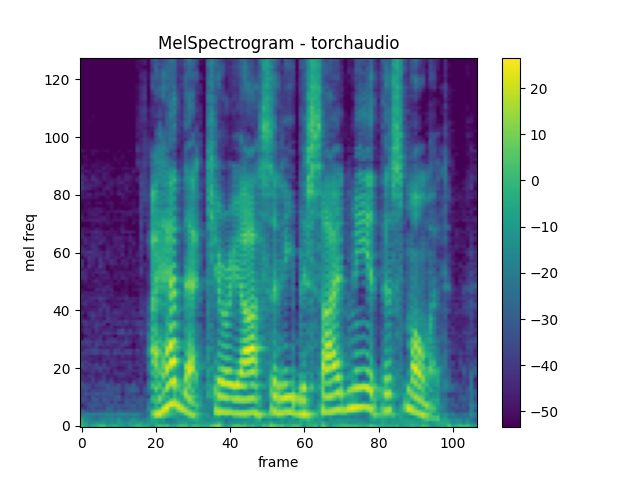
Generating a mel-scale spectrogram involves generating a spectrogram and performing mel-scale conversion. In `torchaudio`, `MelSpectrogram` provides this functionality.
waveform, sample\_rate = get\_speech\_sample()
n\_fft = 1024 win\_length = None hop\_length = 512 n\_mels = 128
mel\_spectrogram = T.MelSpectrogram( sample\_rate=sample\_rate, n\_fft=n\_fft, win\_length=win\_length, hop\_length=hop\_length, center=True, pad\_mode="reflect", power=2.0, norm='slaney', onesided=True, n\_mels=n\_mels, mel\_scale="htk", )
melspec = mel\_spectrogram(waveform) plot\_spectrogram( melspec\[0], title="MelSpectrogram - torchaudio", ylabel='mel freq')
#### Comparison against librosa
For reference, here is the equivalent means of generating mel-scale spectrograms with `librosa`.
melspec\_librosa = librosa.feature.melspectrogram( waveform.numpy()\[0], sr=sample\_rate, n\_fft=n\_fft, hop\_length=hop\_length, win\_length=win\_length, center=True, pad\_mode="reflect", power=2.0, n\_mels=n\_mels, norm='slaney', htk=True, ) plot\_spectrogram( melspec\_librosa, title="MelSpectrogram - librosa", ylabel='mel freq')
mse = torch.square(melspec - melspec\_librosa).mean().item() print('Mean Square Difference: ', mse)

Out:
Mean Square Difference: 1.17573561997375e-10
### MFCC
waveform, sample\_rate = get\_speech\_sample()
n\_fft = 2048 win\_length = None hop\_length = 512 n\_mels = 256 n\_mfcc = 256
mfcc\_transform = T.MFCC( sample\_rate=sample\_rate, n\_mfcc=n\_mfcc, melkwargs={ 'n\_fft': n\_fft, 'n\_mels': n\_mels, 'hop\_length': hop\_length, 'mel\_scale': 'htk', } )
mfcc = mfcc\_transform(waveform)
plot\_spectrogram(mfcc\[0])
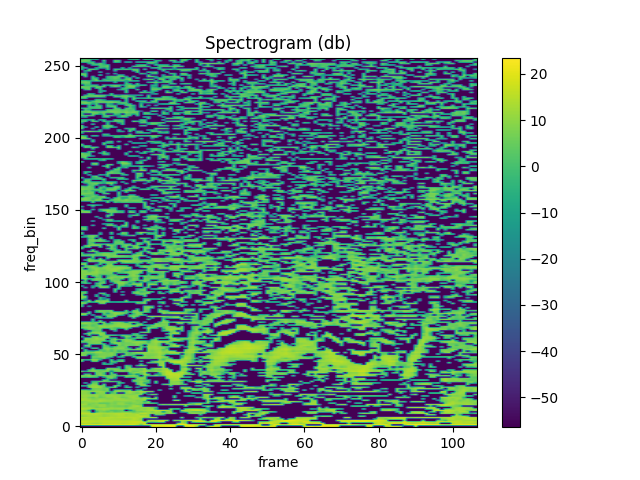
#### Comparing against librosa
melspec = librosa.feature.melspectrogram( y=waveform.numpy()\[0], sr=sample\_rate, n\_fft=n\_fft, win\_length=win\_length, hop\_length=hop\_length, n\_mels=n\_mels, htk=True, norm=None)
mfcc\_librosa = librosa.feature.mfcc( S=librosa.core.spectrum.power\_to\_db(melspec), n\_mfcc=n\_mfcc, dct\_type=2, norm='ortho')
plot\_spectrogram(mfcc\_librosa)
mse = torch.square(mfcc - mfcc\_librosa).mean().item() print('Mean Square Difference: ', mse)
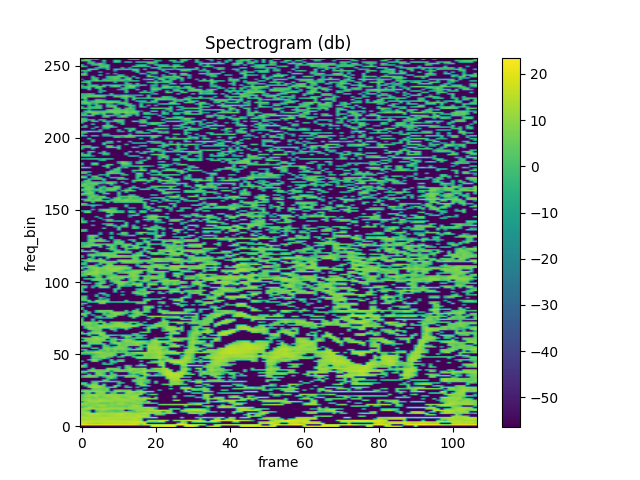
Out:
Mean Square Difference: 4.258112085153698e-08
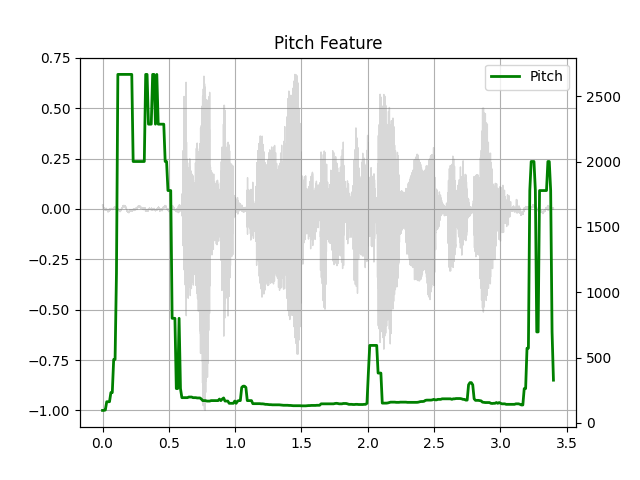
### Pitch
waveform, sample\_rate = get\_speech\_sample()
pitch = F.detect\_pitch\_frequency(waveform, sample\_rate) plot\_pitch(waveform, sample\_rate, pitch) play\_audio(waveform, sample\_rate)

Out:
\
### Kaldi Pitch (beta)
Kaldi Pitch feature \[1] is a pitch detection mechanism tuned for automatic speech recognition (ASR) applications. This is a beta feature in `torchaudio`, and it is available only in `functional`.
1. A pitch extraction algorithm tuned for automatic speech recognition
Ghahremani, B. BabaAli, D. Povey, K. Riedhammer, J. Trmal and S. Khudanpur
2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, 2014, pp. 2494-2498, doi: 10.1109/ICASSP.2014.6854049. \[[abstract](https://ieeexplore.ieee.org/document/6854049)], \[[paper](https://danielpovey.com/files/2014_icassp_pitch.pdf)]
waveform, sample\_rate = get\_speech\_sample(resample=16000)
pitch\_feature = F.compute\_kaldi\_pitch(waveform, sample\_rate) pitch, nfcc = pitch\_feature\[..., 0], pitch\_feature\[..., 1]
plot\_kaldi\_pitch(waveform, sample\_rate, pitch, nfcc) play\_audio(waveform, sample\_rate)
Out:
\
**Total running time of the script:** ( 0 minutes 6.007 seconds)
[Gallery generated by Sphinx-Gallery](https://sphinx-gallery.readthedocs.io)
{% embed url="" %}
---
# Agent Instructions
This documentation is published with GitBook. GitBook is the documentation platform designed so that both humans and AI agents can read, navigate, and reason over technical content effectively. Learn more at gitbook.com.
## Querying This Documentation
If you need additional information that is not directly available in this page, you can query the documentation dynamically by asking a question.
Perform an HTTP GET request on the current page URL with the `ask` query parameter, and the optional `goal` query parameter:
```
GET https://bryan-guner.gitbook.io/my-docs/ai/pytorch.md?ask=&goal=
```
`ask` is the immediate question: it should be specific, self-contained, and written in natural language.
`goal` is optional and describes the broader end goal you are ultimately trying to accomplish on behalf of the user. GitBook uses it to tailor the answer towards what is most useful for that goal.
The response will contain a direct answer to the question and relevant excerpts and sources from the documentation.
Use this mechanism when the answer is not explicitly present in the current page, you need clarification or additional context, or you want to retrieve related documentation sections.